What are Naïve Bayes classifiers?
A Naïve Bayes classifier is a simple algorithm for classifying data based on Bayes’ theorem. It is considered to be a supervised machine learning algorithm that belongs to the statistical family of classifiers.
The word Naïve refers to the naïve assumption of feature independence; that is, the theory assumes that the values of one feature are not affected by or dependent on the presence or properties of the other features.
A Naïve Bayes classifier uses the below equation (Bayes’ theorem) to calculate the probability of a specific event occurring given a specific set of features values.

P(predictor | target): is the probability of this target value giving this predictor value.
P(target): is the probability of target value.
P(predictor): is the probability of this predictor value.
P(target| predictor): is the predicted probability of target giving predictor.
How does it work?
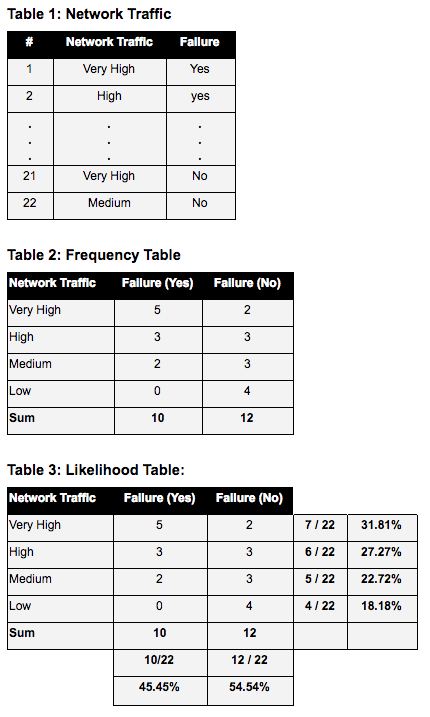
Let’s assume that we have the below dataset of “Network Traffic” and “network failure” events (table 1), and we want to estimate the probability of a “Network Failure” occurring under the condition of “very high” network traffic.
The first step is to convert the data table into a frequency table (table 2). The frequency table represents the counts of each category of the “Network Traffic” values grouped by the target feature “Failure”.
The second step is to calculate the likelihood of the feature and the target (table 3). This done by calculating the probability of each feature’s value in the whole dataset.
The third step is substituting the outputs from the first and second steps into the Naïve Bayes equation:

So there is a high probability (71%) of network failure when network traffic is “very high”. Using the same steps; the probability of not having a network failure for a very-high network traffic is .0.29. From both probabilities, the classifier will choose the class with the higher probability (network-Failure = yes).