Overfitting, Variance, Bias and Model Complexity in Machine Learning
How complex should a machine learning model be? How much complexity can we tolerate before we start to suffer from over-fitting? These questions can be assessed by comparing how models perform on training and validation data as model complexity is increased or reduced.
More complex models will, in general, perform better on training data than simpler ones. Complex models have more parameters that can be adjusted during training to get a good fit to the desired result. Therefore, their error-rate when measured on the data-set used for training will usually be lower.
However, a model that is too complex can end up over-fitting to random effects that are present only in the specific data-set used for training. If these random effects are not present in new data when the model is asked to make predictions, then the model will produce incorrect results when it tries to use them. To judge whether this is happening, measure the model's error-rate on a validation data-set that was not used during training.
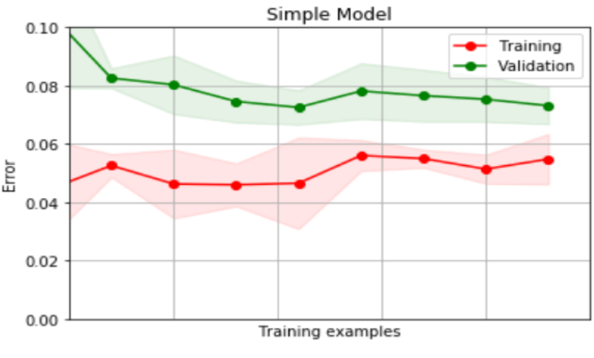
- A high error-rate on both training and validation data indicates that the model may be too simple to faithfully capture any relationships present in the data. In this case, the model is said to have high bias.
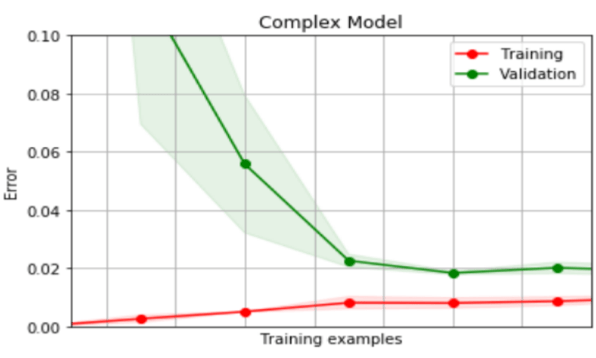
- If the error-rate is low on training data but high on validation data, then the model may be too complex - it suffers from high variance.
A complex model exhibiting high variance may improve in performance if trained on more data samples. Learning curves, which show how model performance changes with the number of training samples, are a useful tool for studying the trade-off between bias and variance.
Typically, the error-rate on training data starts off low when the number of samples is small, and increases as more samples are used (because a larger training set is harder to fit to). On the other hand, the error-rate on validation data is typically high for a model trained on very few samples and decreases with more training (because the relationships learned during training are more likely to be valid for new data).
If the validation error-rate remains much higher than the training data error rate even when the training set is large, then the model is over-fitting and could benefit from reduced complexity. There are several ways to vary the complexity of a model to try to improve its performance:
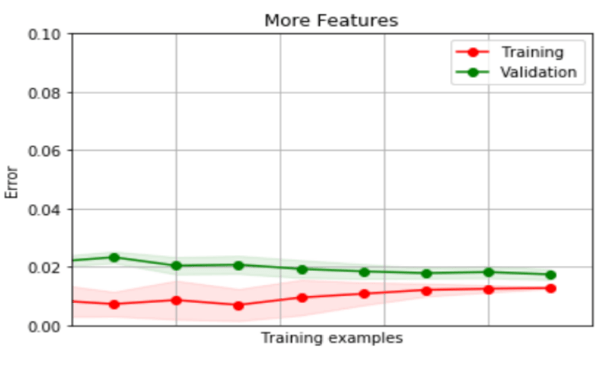
- Using fewer features reduces model complexity. However, inadvertently removing key features that are important for prediction can quickly make your model too simplistic to perform well. An alternative is to apply regularization, which allows the model to exploit all features but penalizes it based on the number it uses.
- Increasing the number and size of layers used in a neural network model, or the number and depth of trees used in a random forest model, increases model complexity.
Figure 1. Learning curves showing measured error for different regression models applied to a prediction problem. The top-most chart is for a simple model which uses very few features but is already reasonably accurate. Adding more features reduces error on both training and validation data (middle chart). But when complexity is increased again with yet more features (bottom chart), training error improves but validation error does not - a sign that the model Is now beginning to over-fit.